Abstract
Universal sound separation faces a fundamental misalignment: models optimized for low-level signal metrics often produce semantically contaminated outputs, failing to suppress perceptually salient interference from acoustically similar sources. We introduce a preference alignment perspective, analogous to aligning LLMs with human intent. To address this, we introduce MARS-Sep, a reinforcement learning framework that reformulates separation as decision making. Instead of simply regressing ground-truth masks, MARS-Sep learns a factorized Beta mask policy that is steered by a preference reward model and optimized by a stable, clipped trust-region surrogate. The reward, derived from a progressively-aligned audio-text-vision encoder, directly incentivizes semantic consistency with query prompts. Extensive experiments on multiple benchmarks demonstrate consistent gains in Text-, Audio-, and Image-Queried separation, with notable improvements in signal metrics and semantic quality. Our code is available at https://anonymous.4open.science/r/MARS-Sep. Sound separation samples are available at https://mars-sep.github.io/.
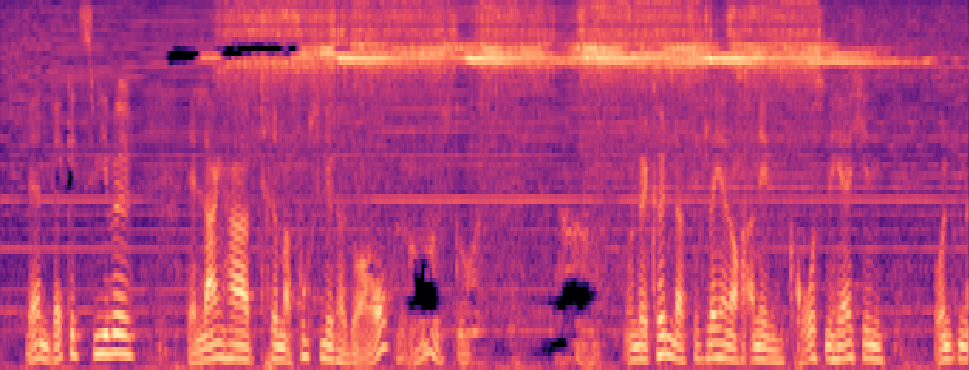
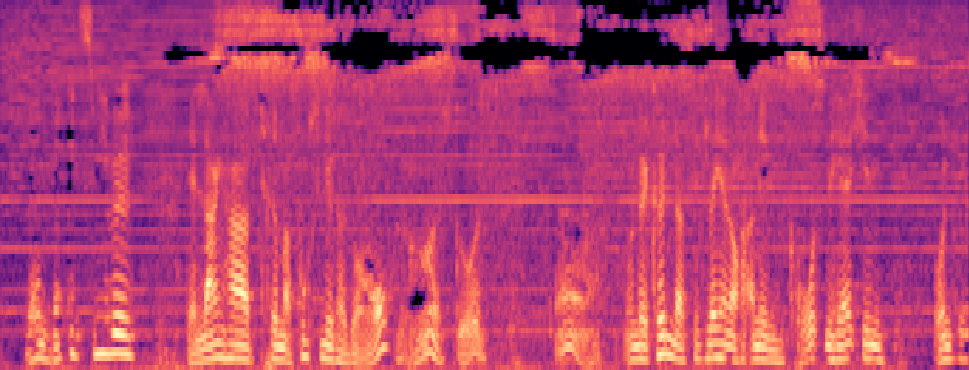
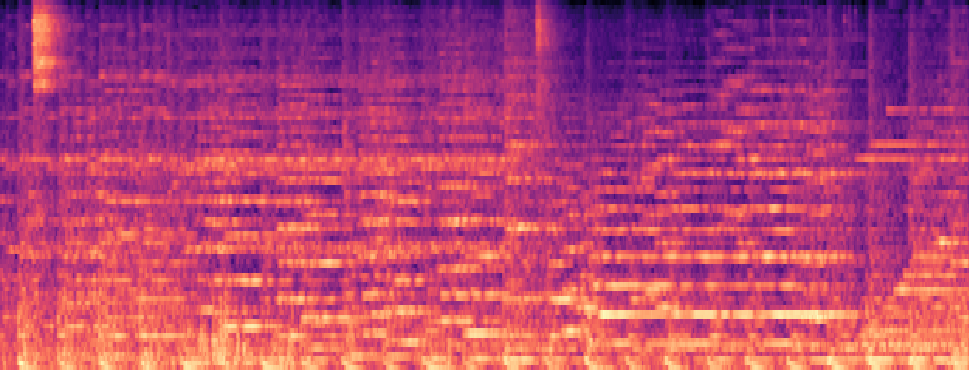
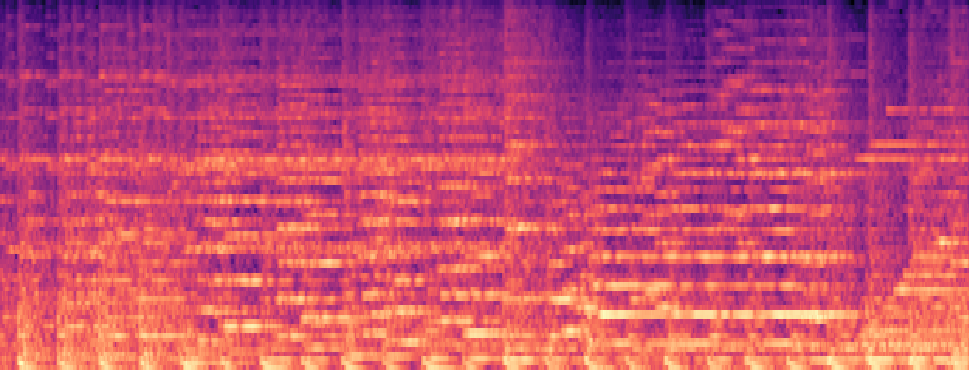
Qualitative samples in the MARS-Sep paper.
| Query | Mixture | Interference | Target | OmniSep | MARS-Sep |
|---|---|---|---|---|---|

|
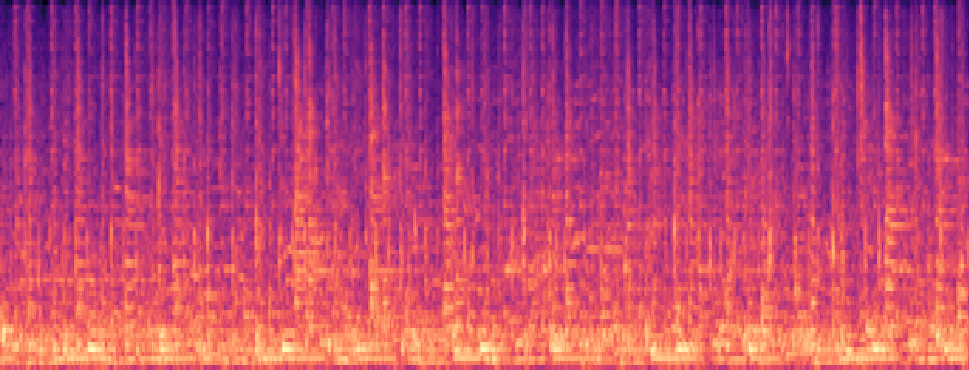
|
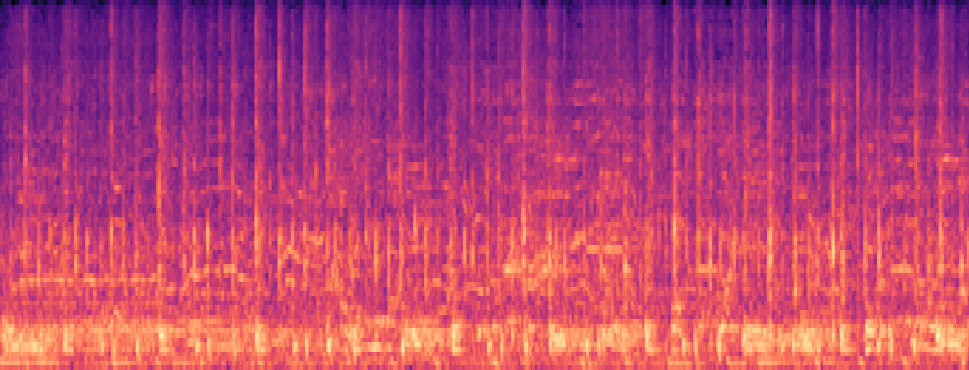
|
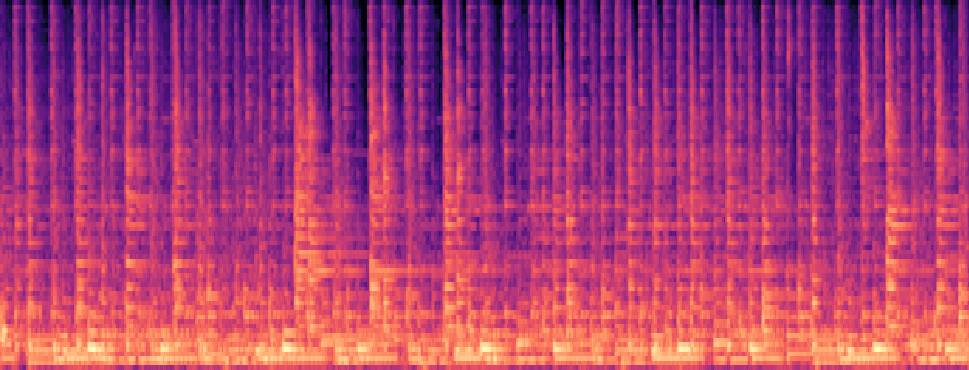
|
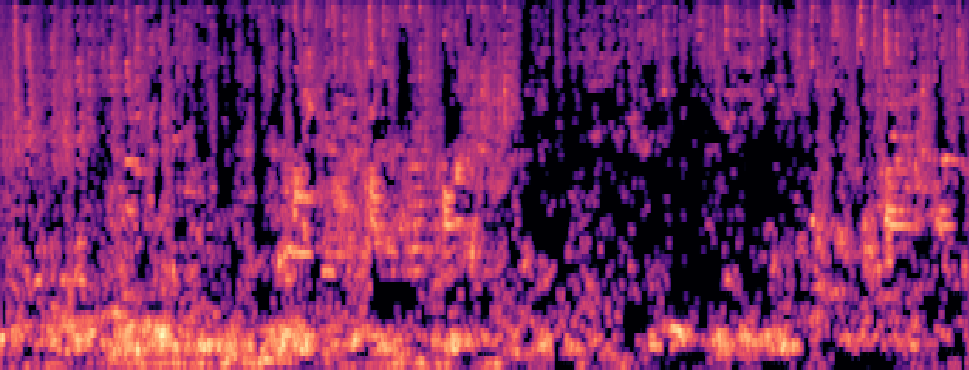
|
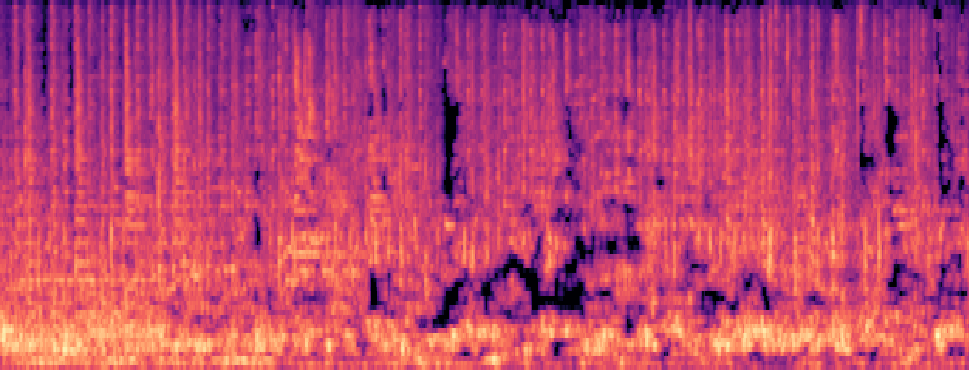
|

|
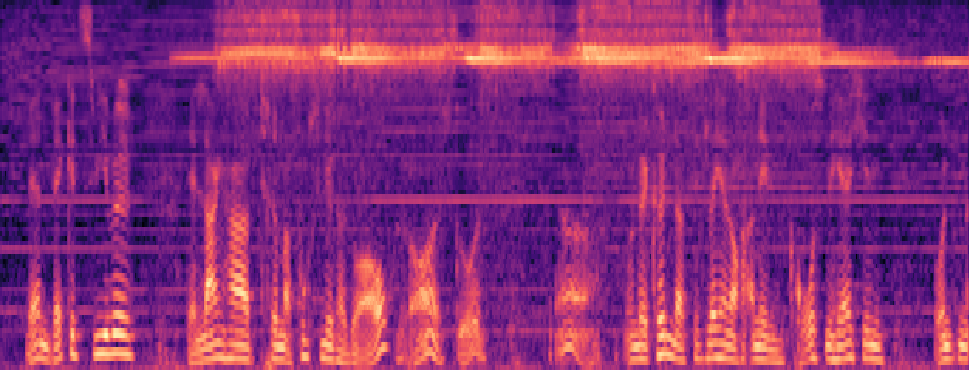
|
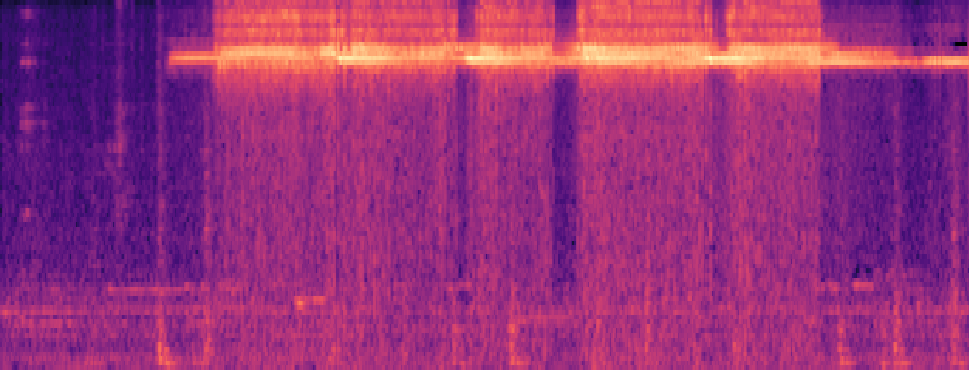
|
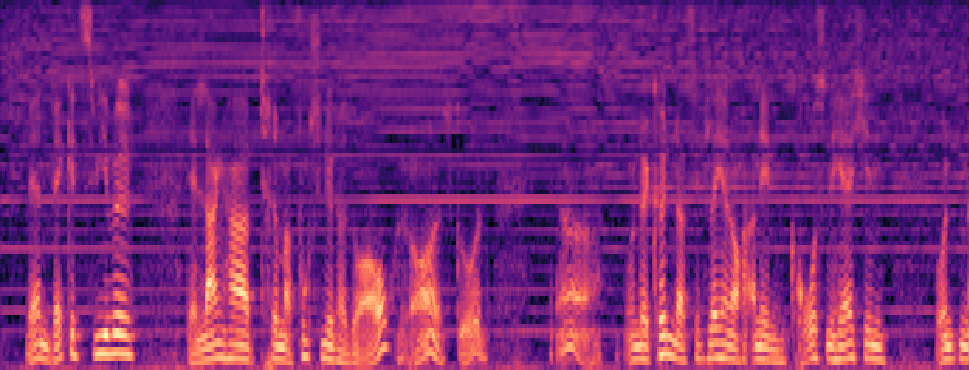
|
|
|

|
|
|
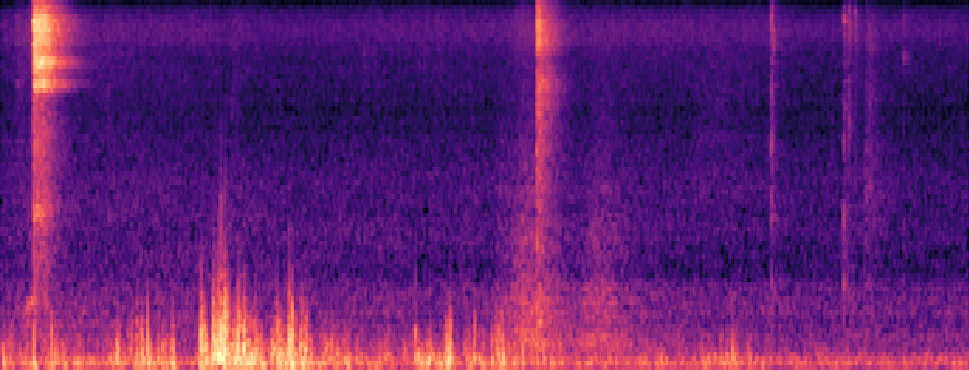
|
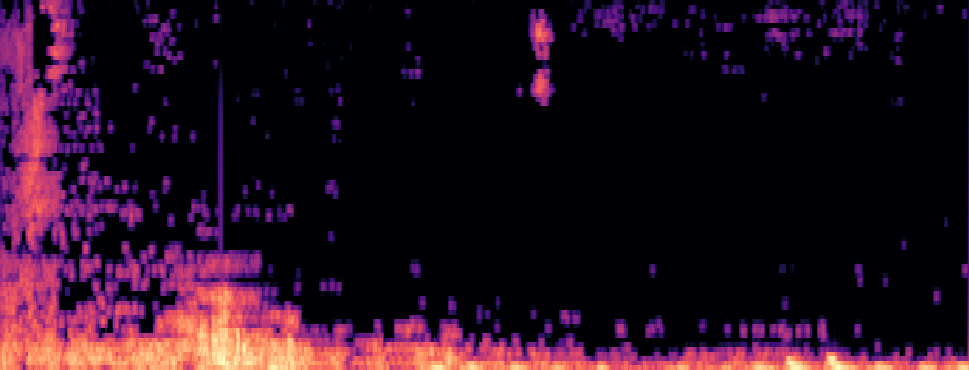
|
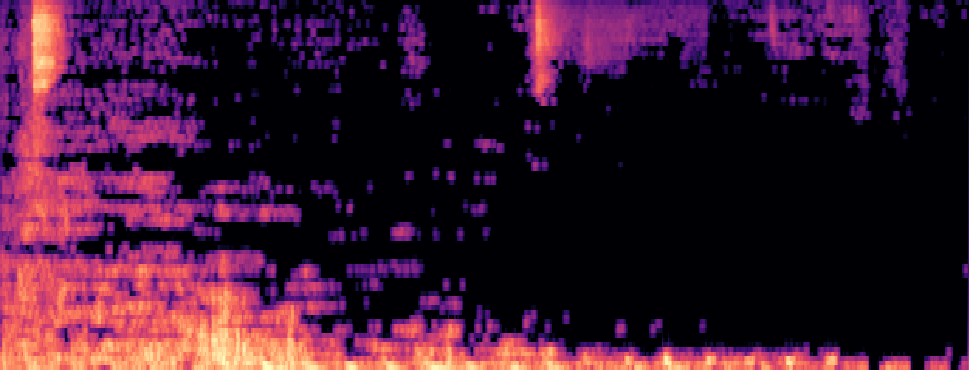
|

|
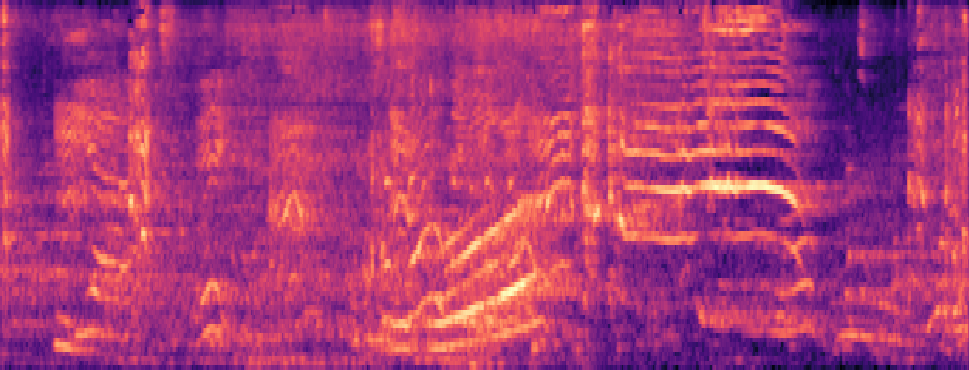
|
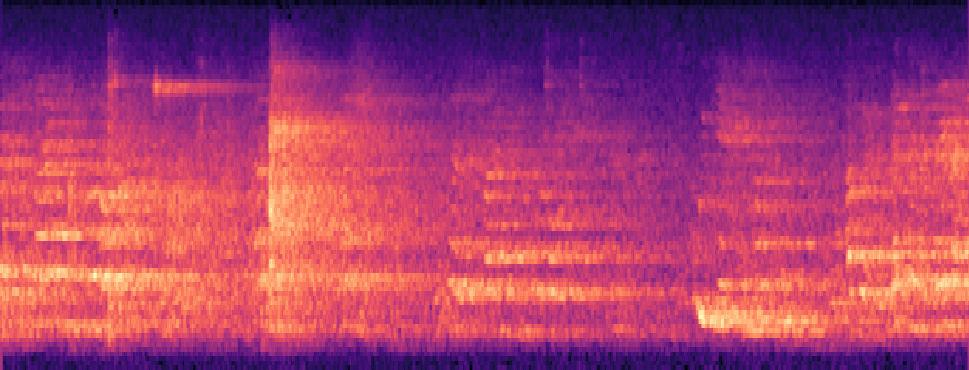
|
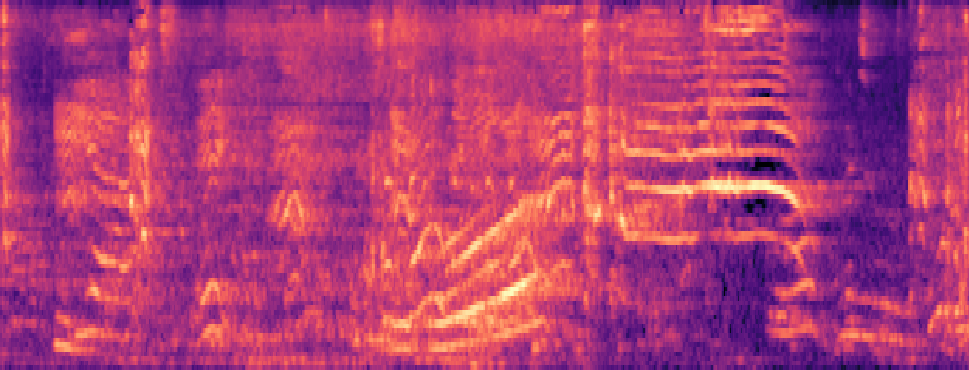
|

|
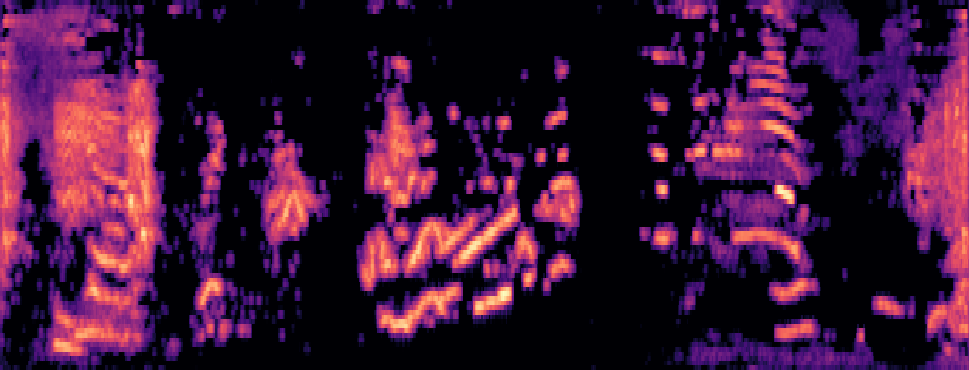
|
More samples with Queries of Different Modalities.
1.Text-Query
| Query | Mixture | Interference | Target | Prediction |
|---|---|---|---|---|

|
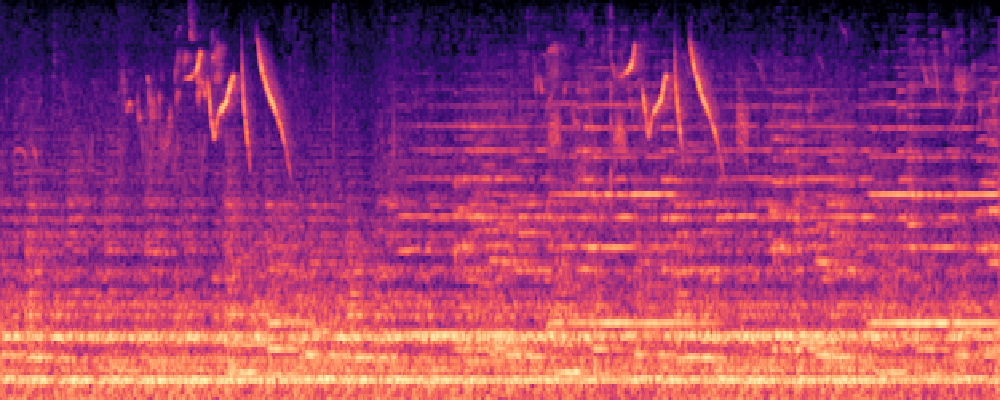
|
|
|
|

|
|
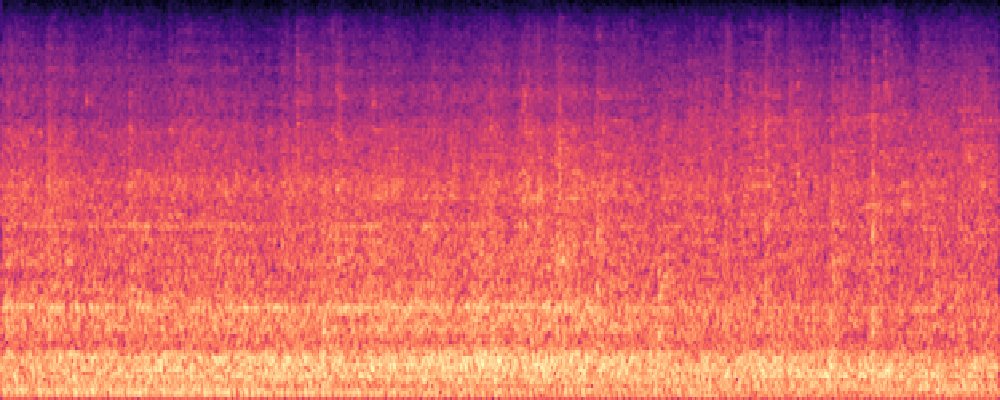
|
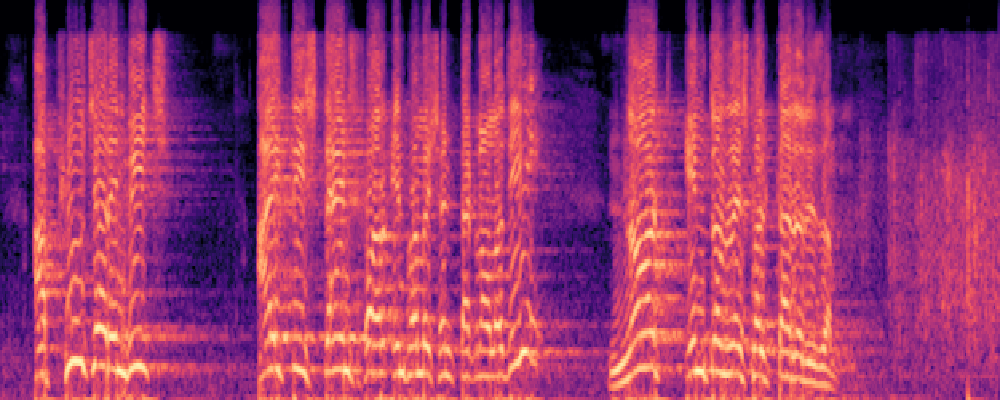
|
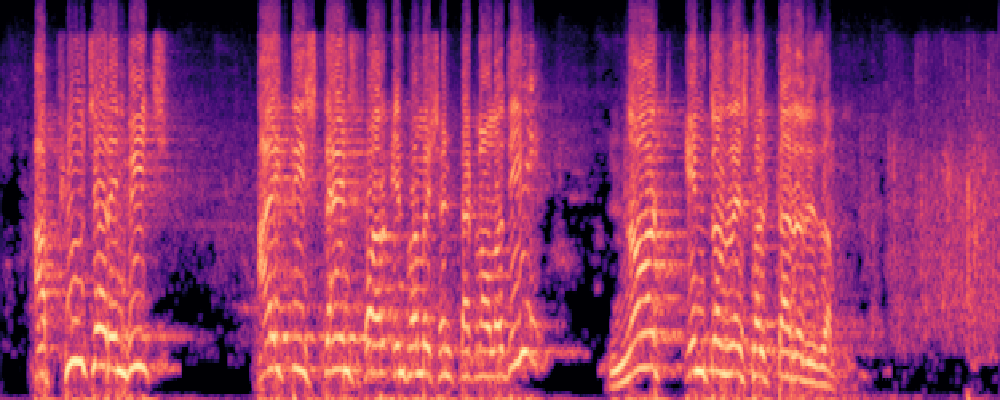
|

|
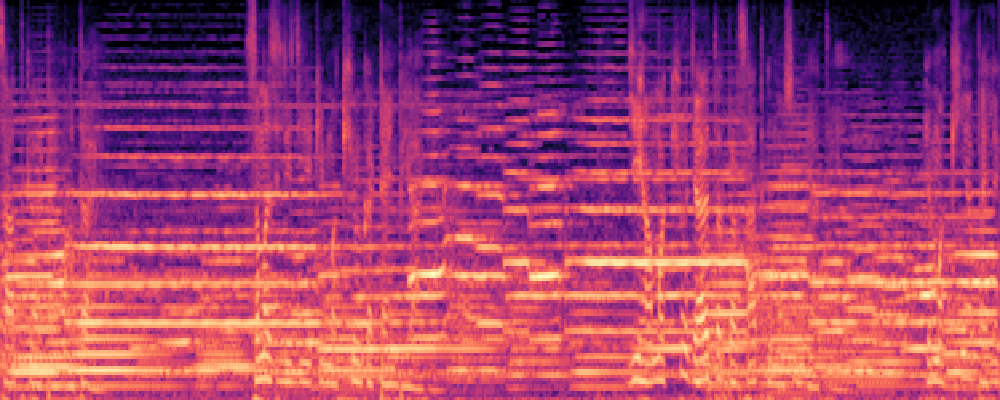
|
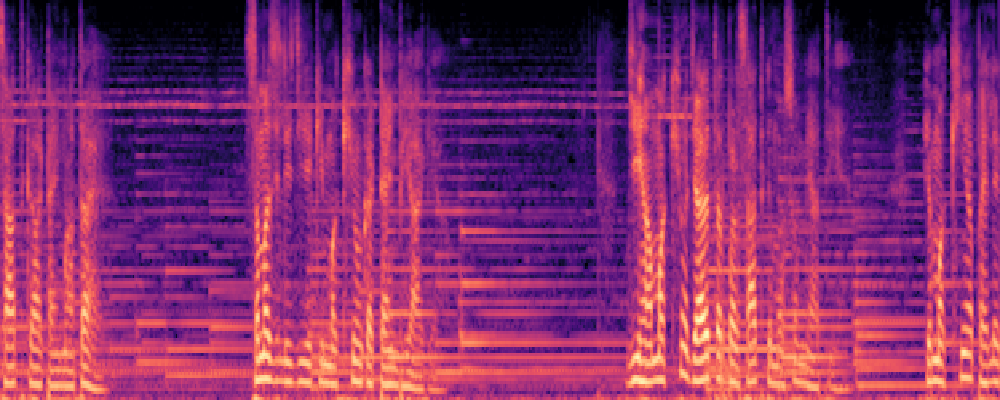
|
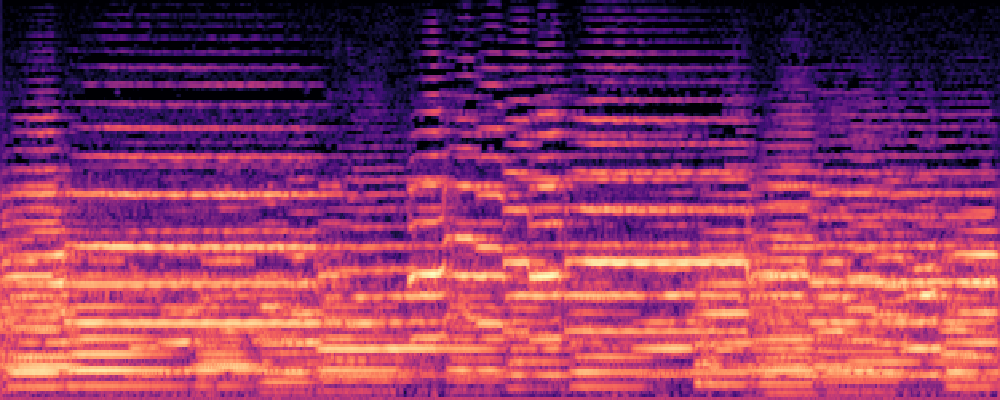
|
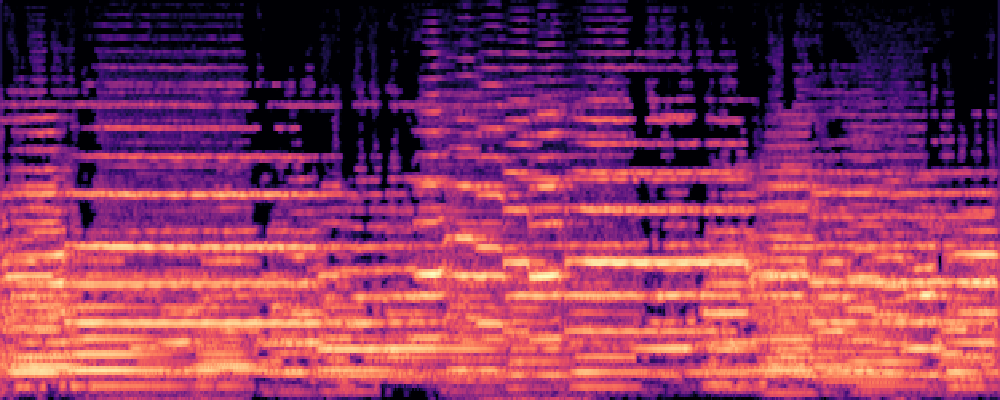
|

|
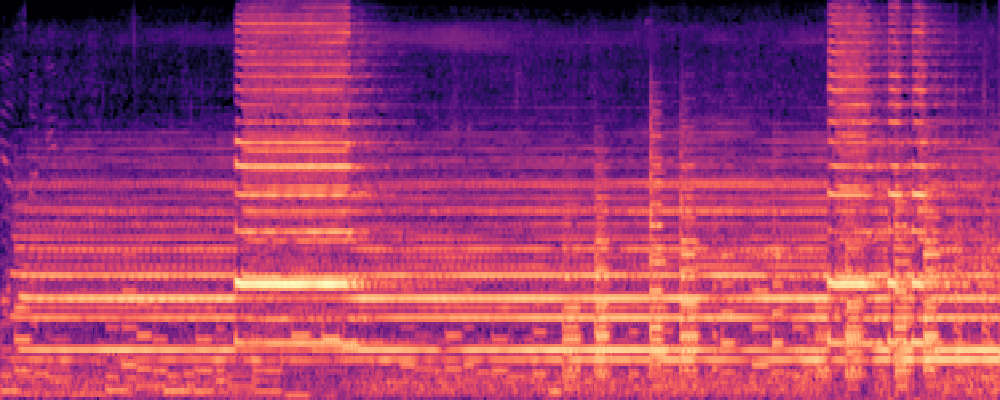
|
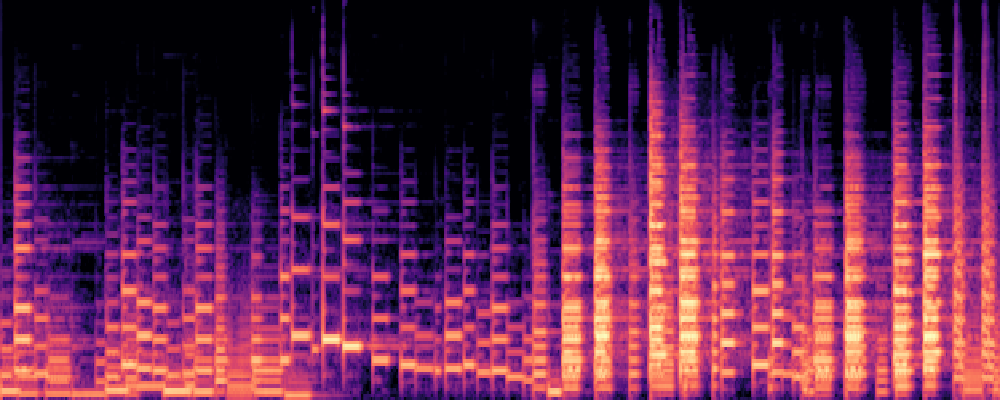
|
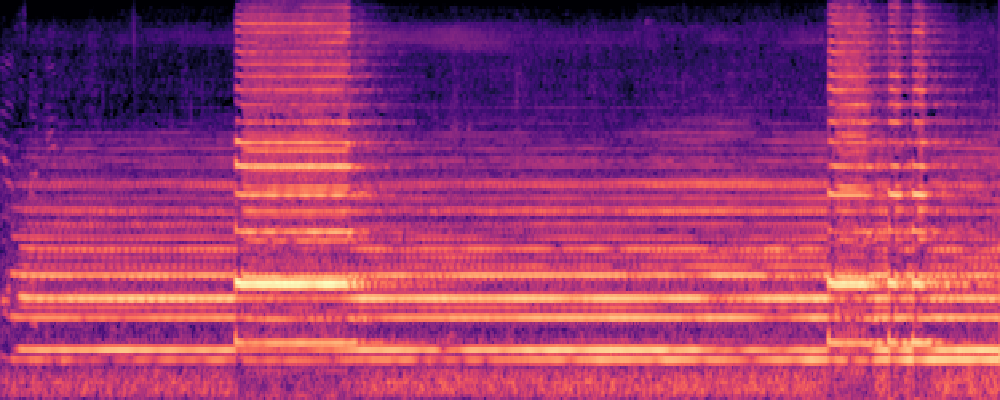
|
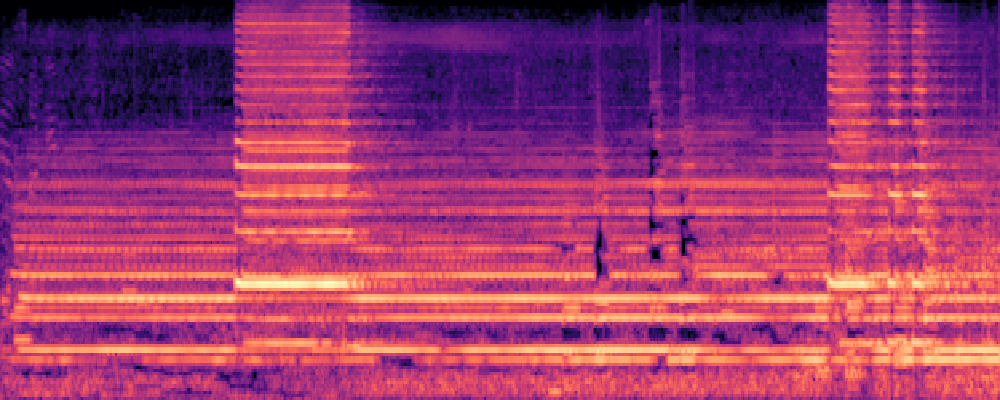
|

|
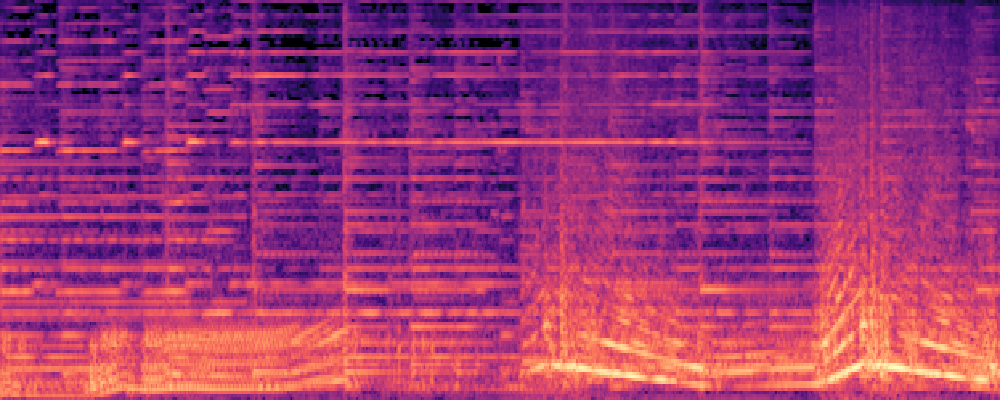
|
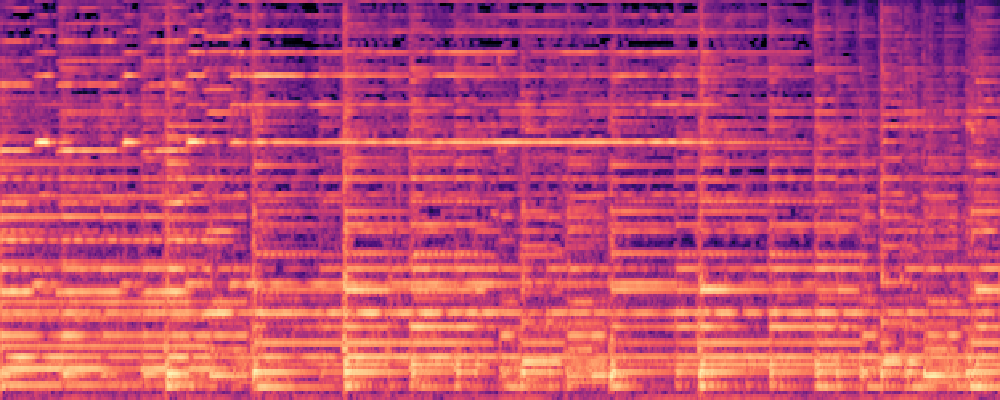
|
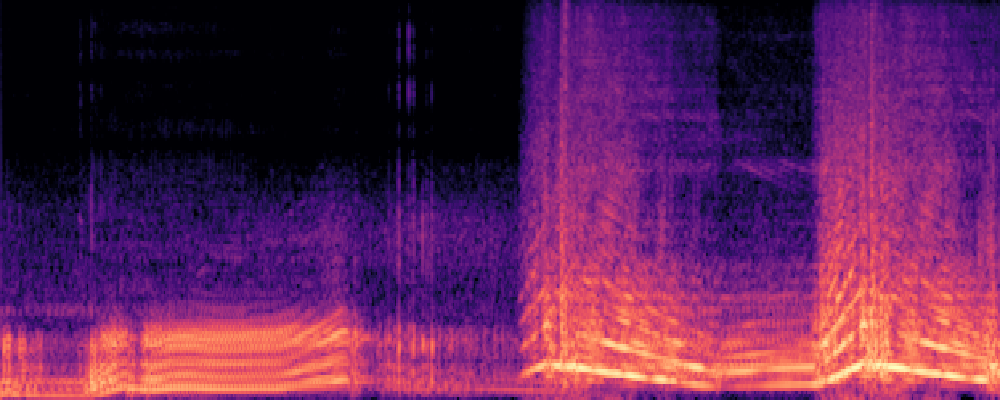
|
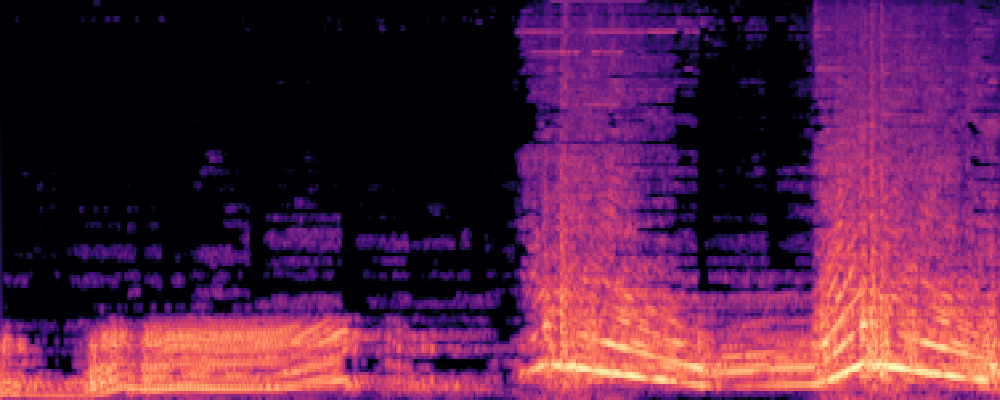
|
2.Image-Query
| Query | Mixture | Interference | Target | Prediction |
|---|---|---|---|---|

|
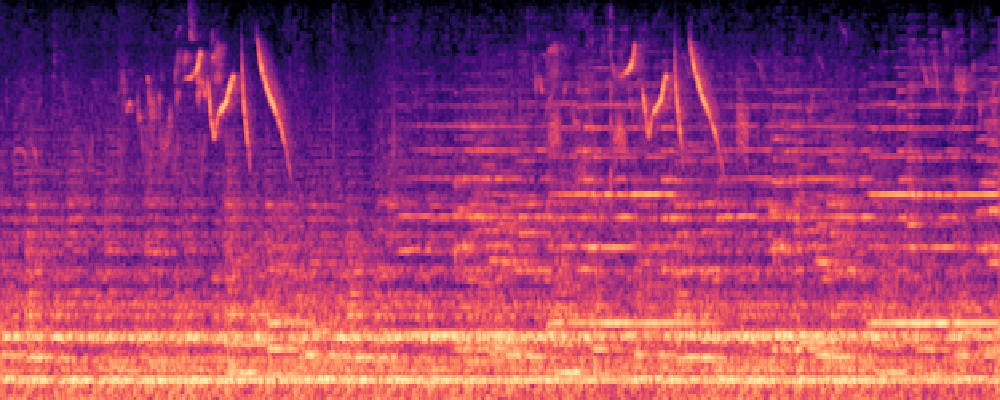
|
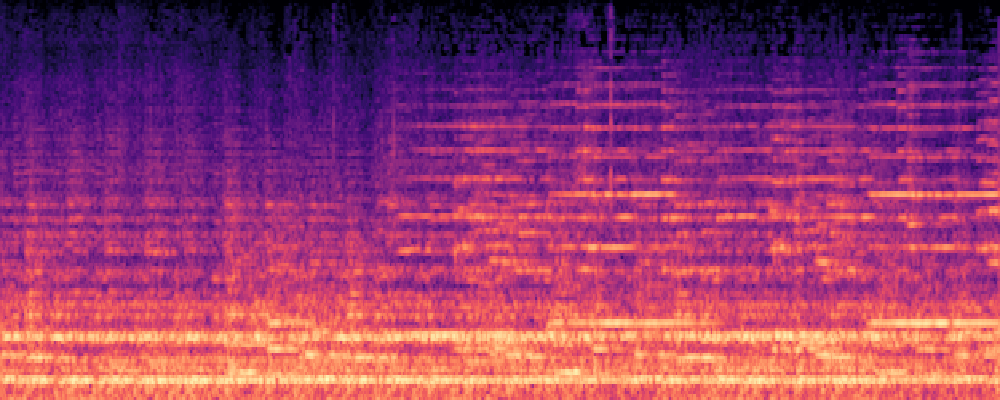
|
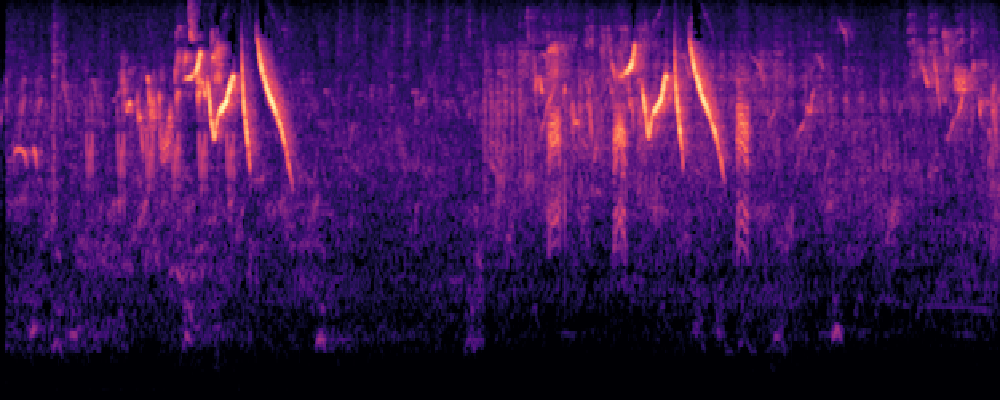
|
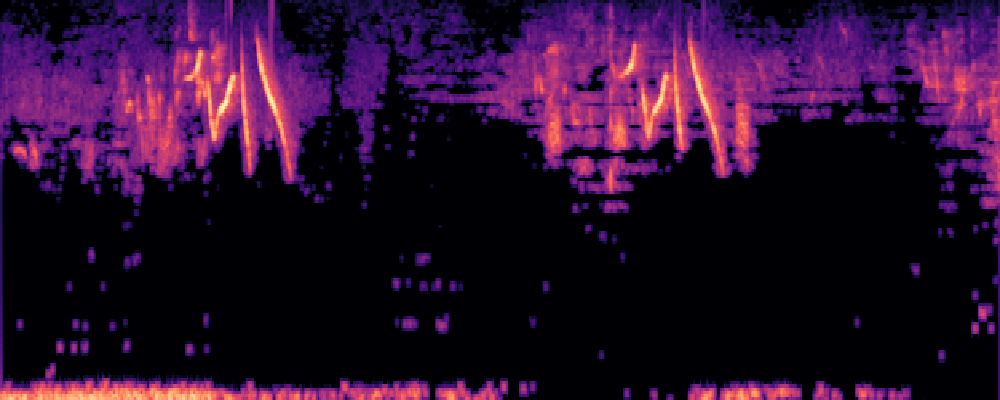
|

|
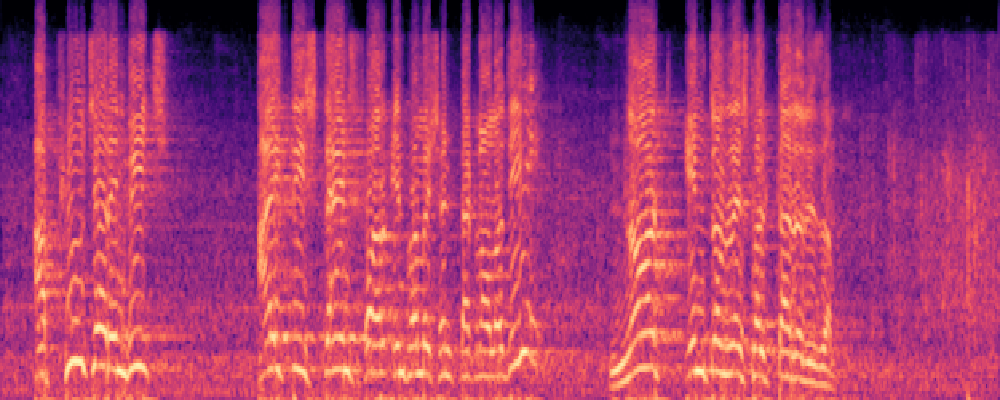
|
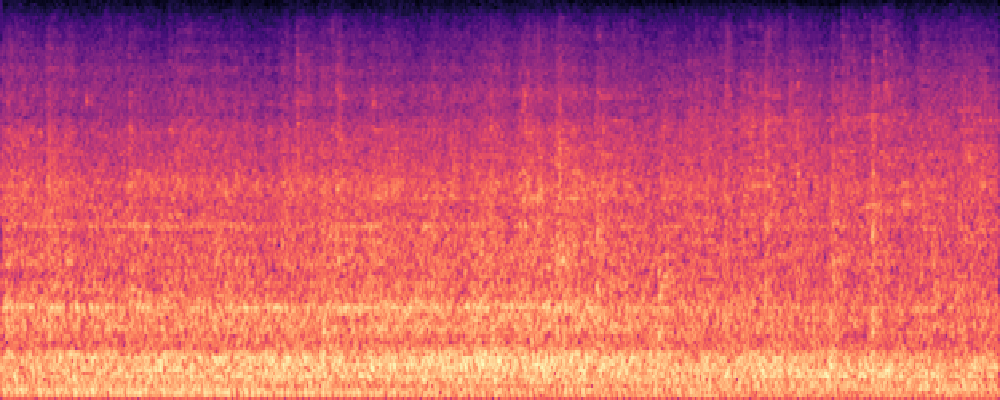
|
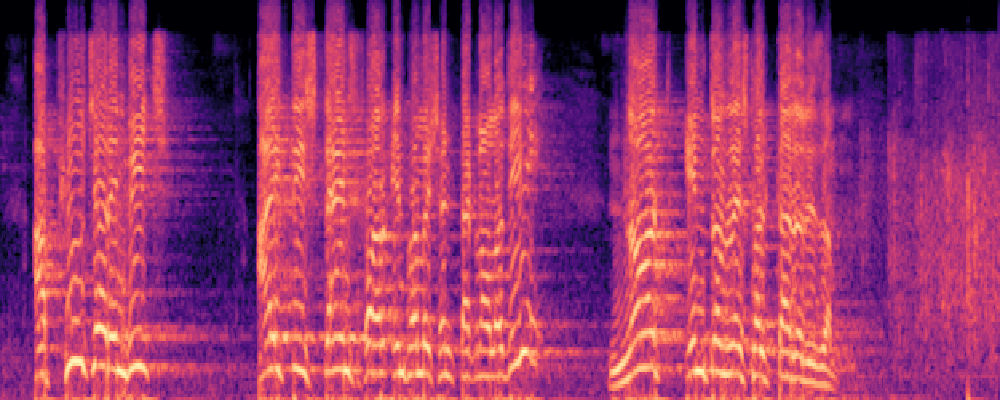
|
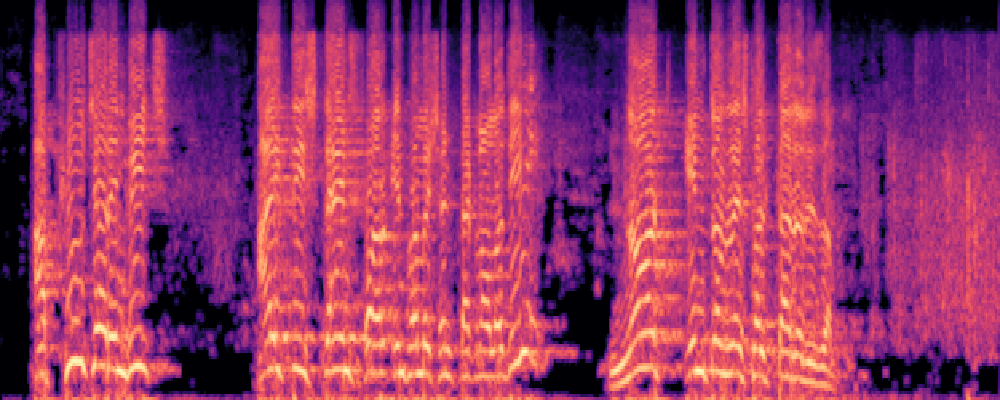
|

|
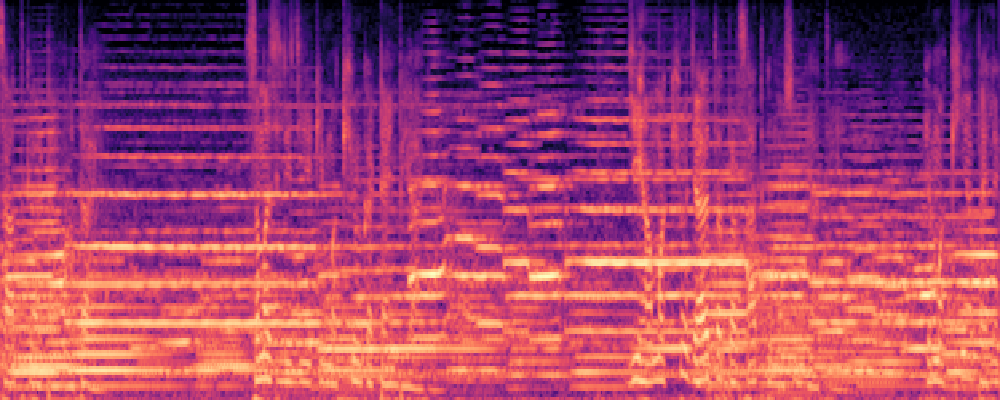
|
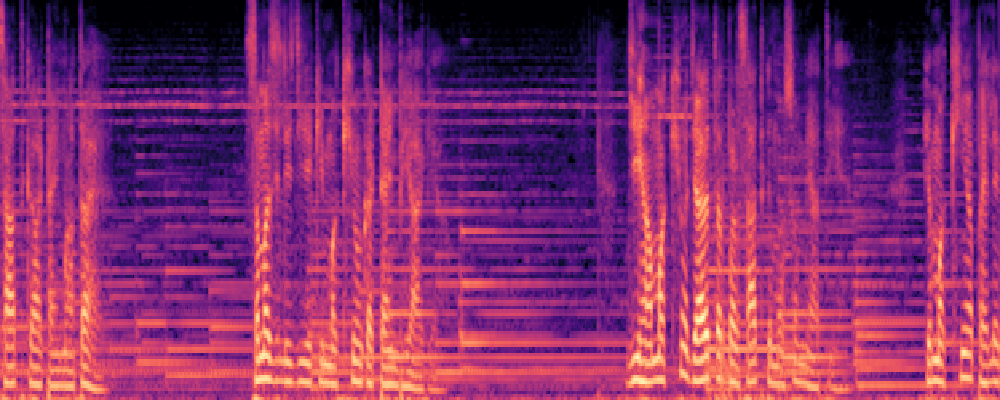
|
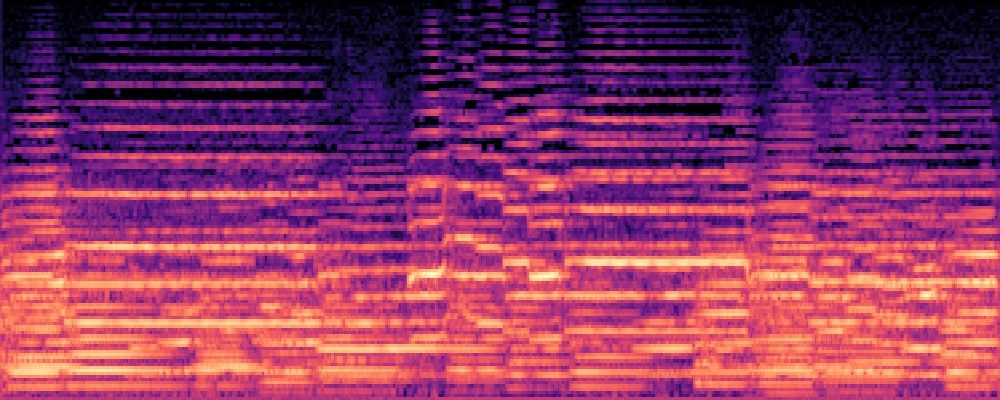
|
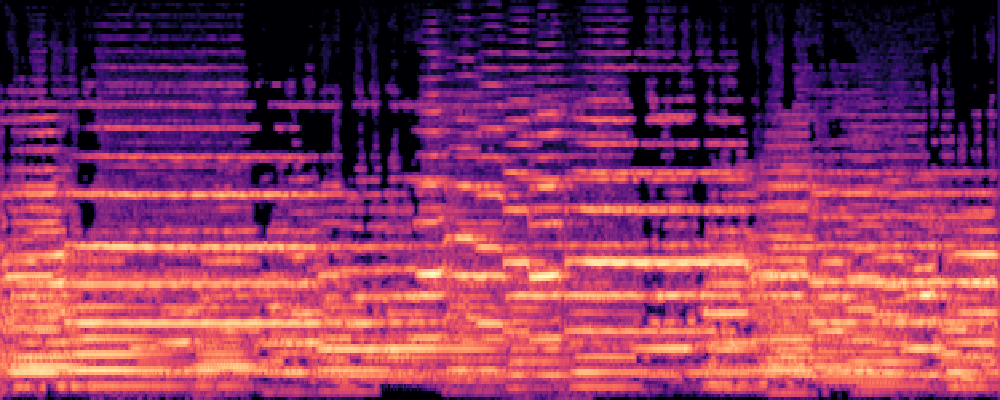
|

|
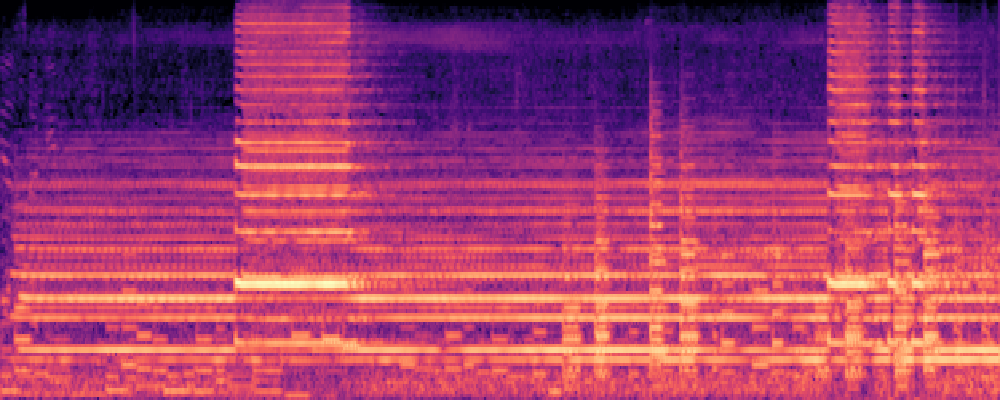
|
|
|
|

|
|
|
|
|
3.Audio-Query
| Query | Mixture | Interference | Target | Prediction |
|---|---|---|---|---|

|
|
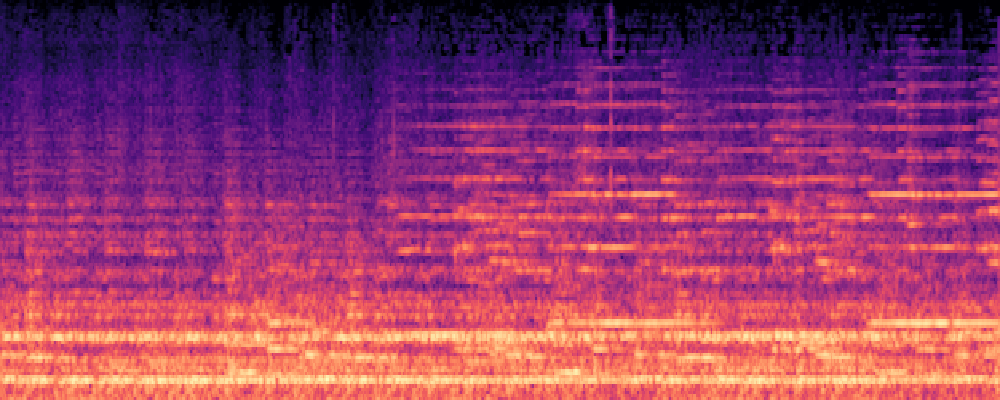
|
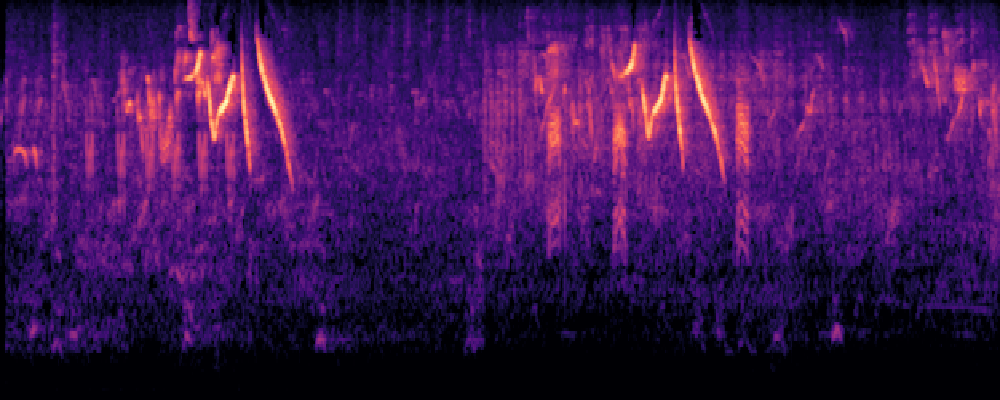
|
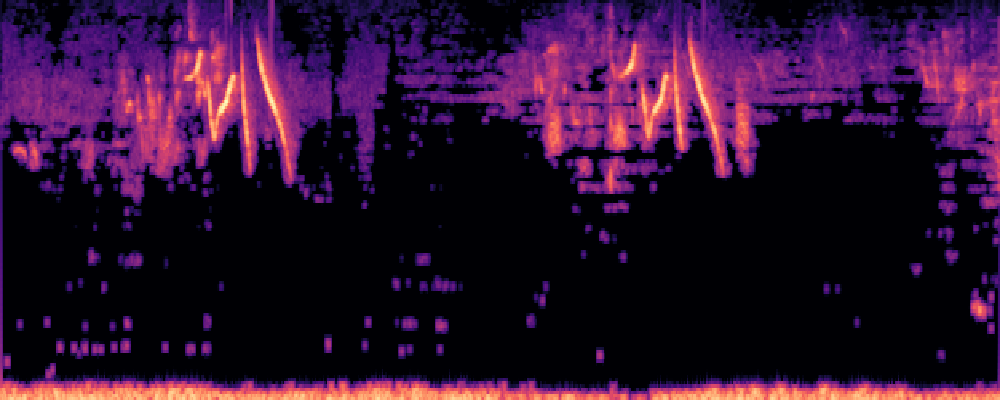
|
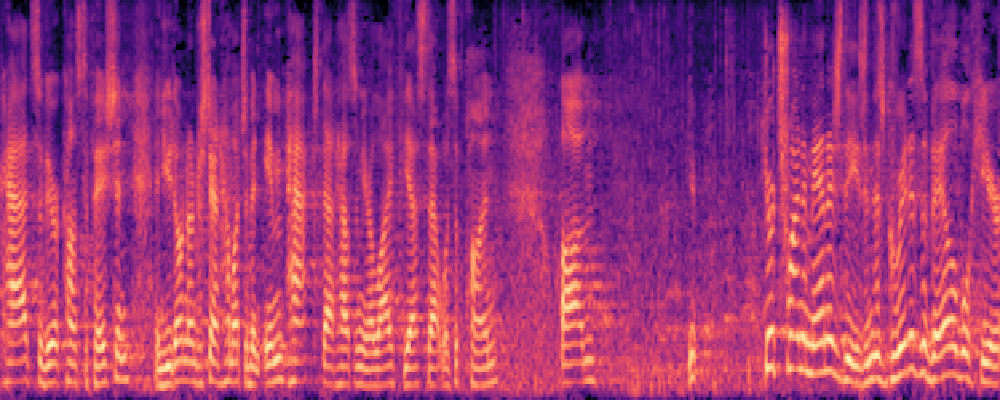
|
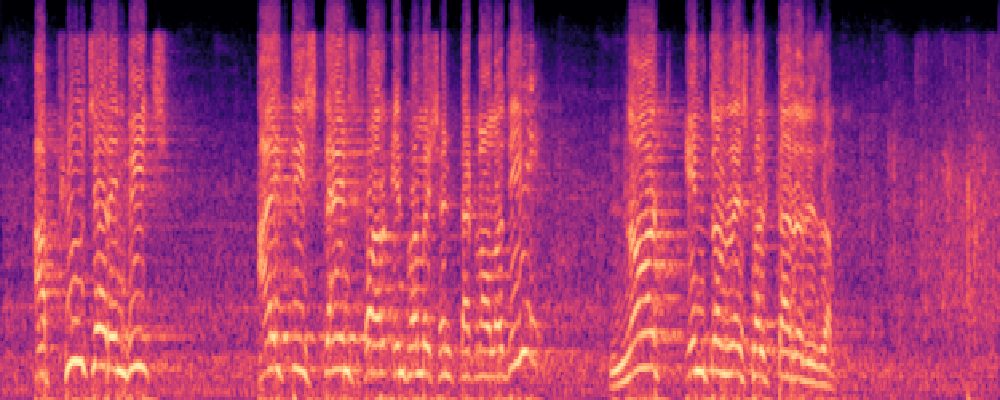
|
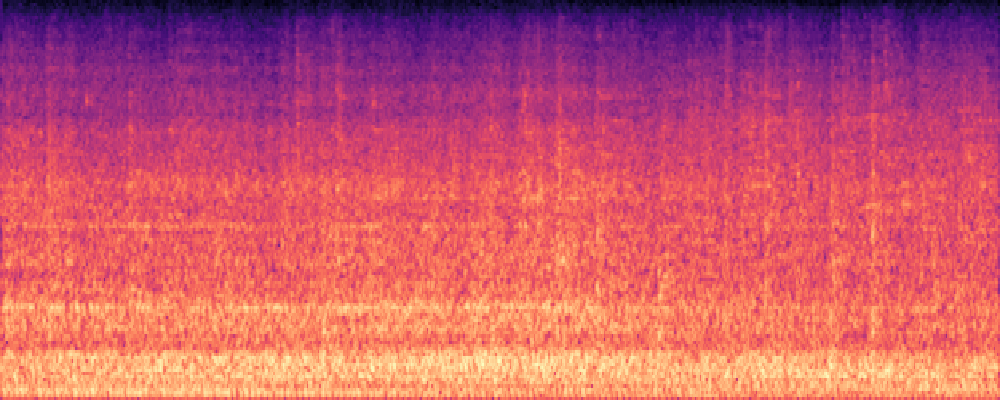
|
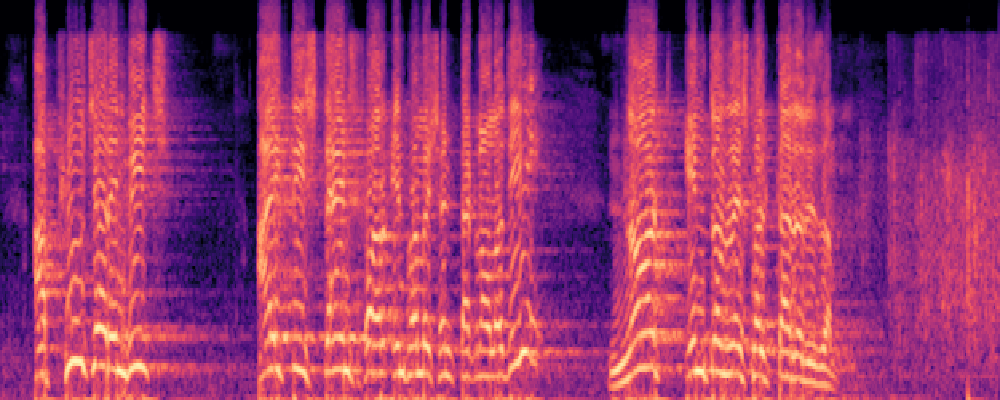
|
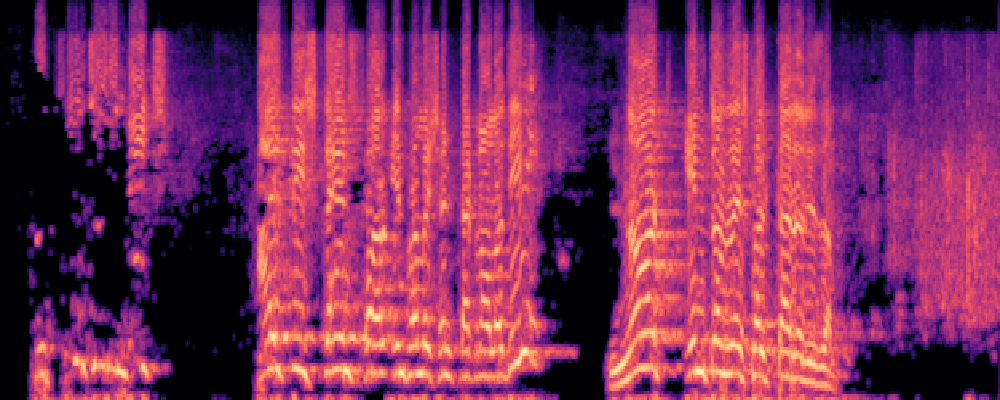
|
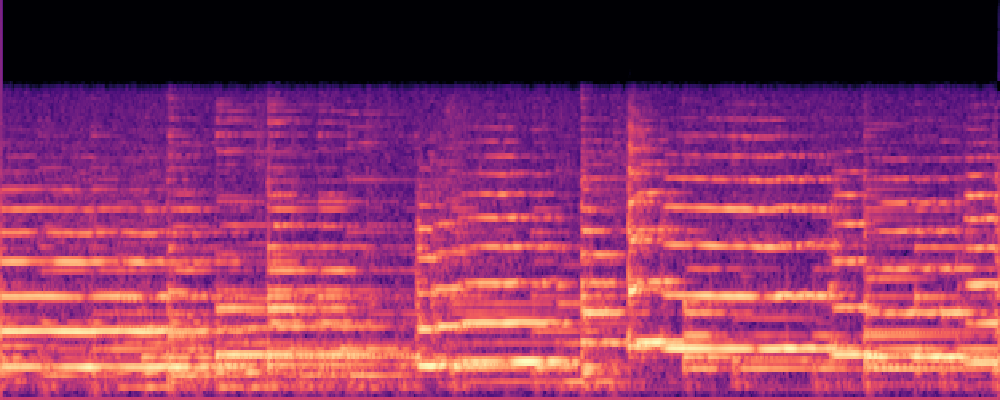
|
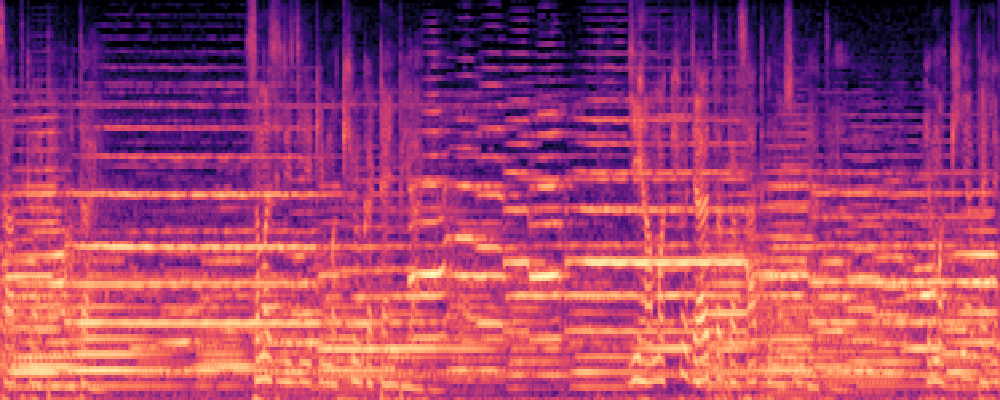
|
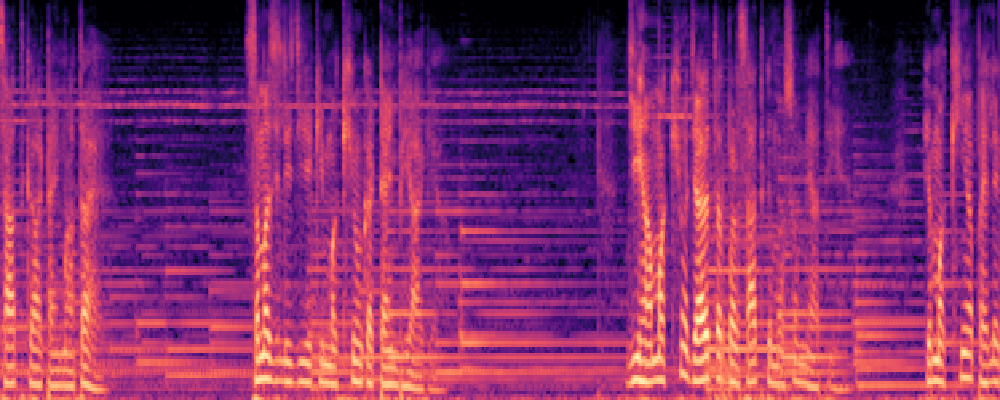
|
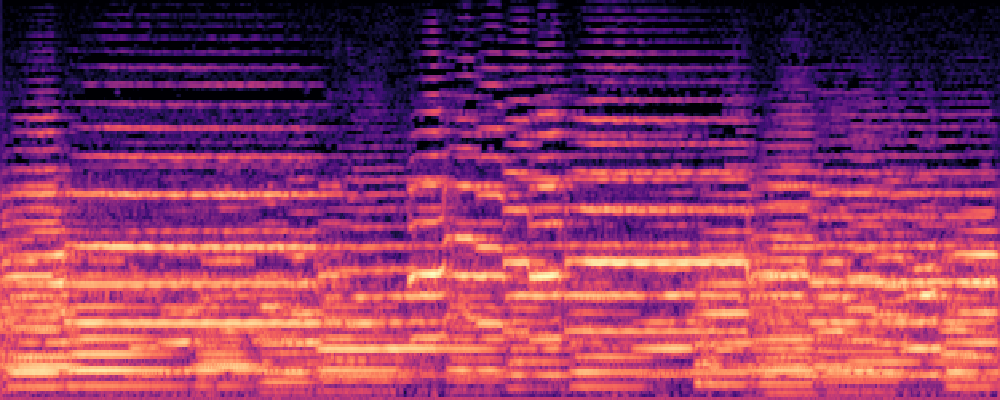
|
|
|
|
|
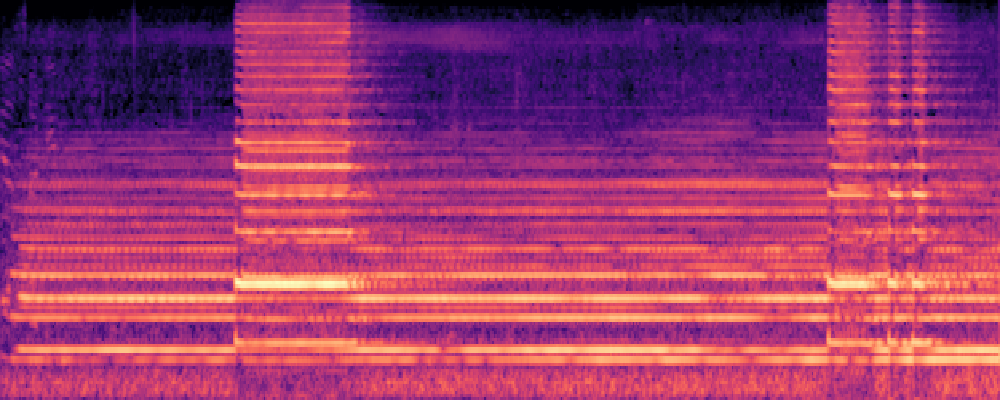
|
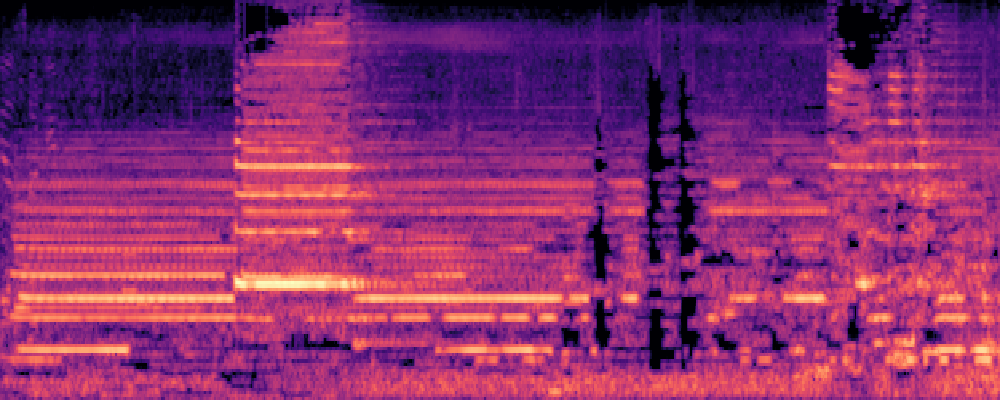
|
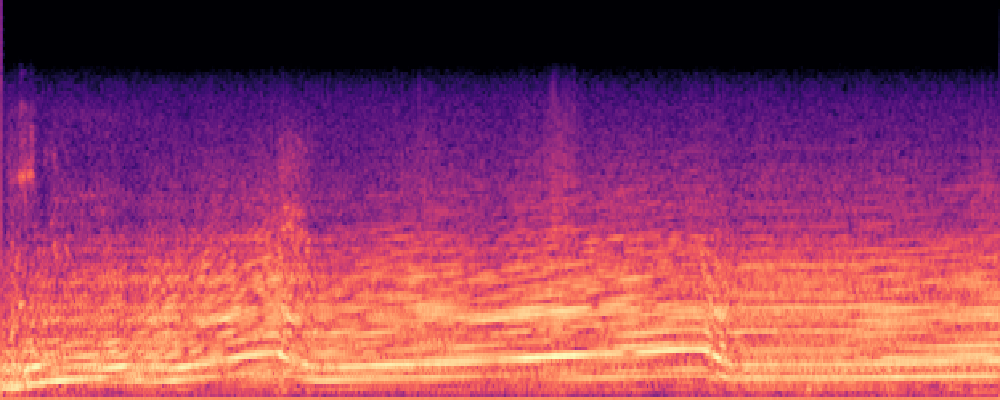
|
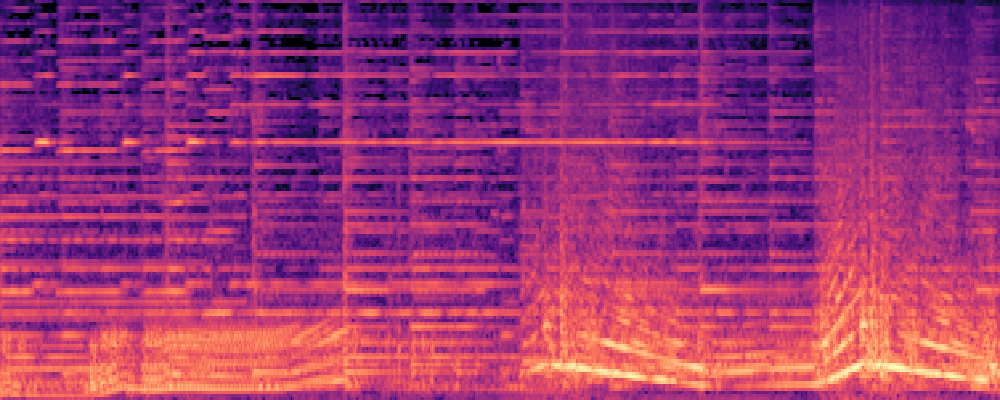
|
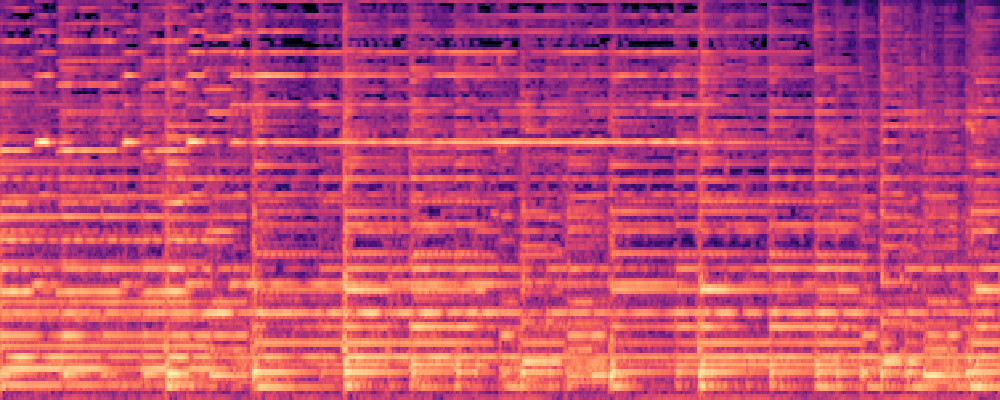
|
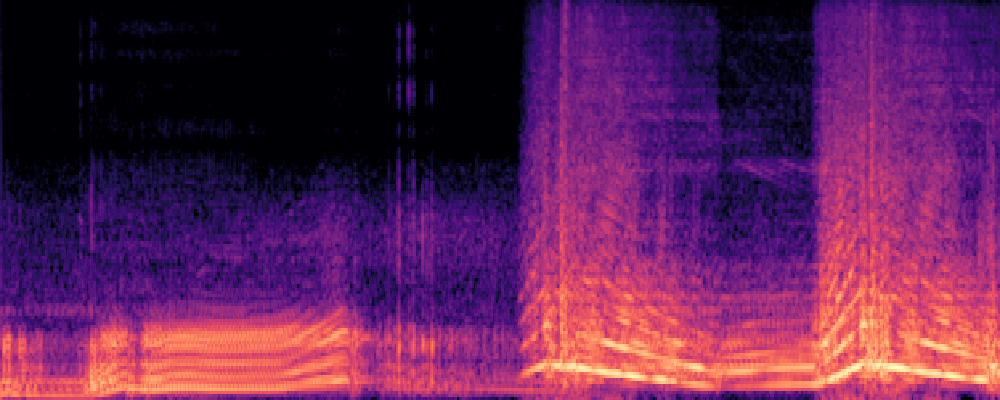
|
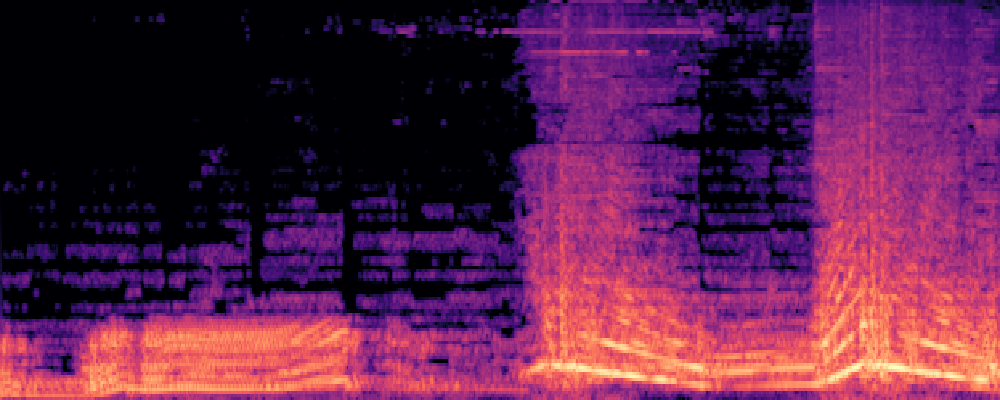
|
More samples in the wild.
| Video | Query (Text/Image/Audio) |
Separated Audio |
|---|---|---|
motorcycle running |
||

|
||
male commentary |
||

|
||
elephant trumpeting |
||

|
||